[Next.js] React Query + SSR로 LCP 92% 개선하기
Frontend/Next.js
· 2025-05-25
![[Next.js] React Query + SSR로 LCP 92% 개선하기](/assets/posts/ssr-react-query/thumbnail-optimized.webp)
들어가며
개인 프로젝트로 AWS App Runner에 배포해둔 백엔드 서버가 하나 있다. 몇 년치 나스닥 상위 대형주들의 주가 데이터를 Neon이라는 DB 서비스에 저장하고 있고, 현재는 증시 마감 시간에 맞춰 매일 Cron 작업을 통해 전날 마감 주가 업로드를 자동화해두었다.
이번 게시글에서는 이 주가 데이터를 Next.js 기반 프론트엔드 애플리케이션에 React Query + SSR 방식으로 효율적으로 렌더링하고, 그 결과로 LCP(Largest Contentful Paint)를 약 92% 개선한 과정을 정리해본다. 특히, SSG와 CSR 방식과 비교했을 때, 초기 페이지 로딩 속도 개선이 어떤 방식으로 이루어졌는지 실제 Lighthouse 분석 결과를 바탕으로 설명할 예정이다.
App Router 기반 프로젝트 구조
프로젝트는 Next.js 15.2 App Router 구조를 기반으로 개발하였다. App Router는 중첩 레이아웃, 서버 컴포넌트 기반의 SSR, SSR-CSR의 유연한 혼합 등 다양한 장점을 제공하기 때문에 Page Router보다 확장성과 유지보수가 좋다. 그렇기 때문에 기존 Page Router에서 사용하던 getServerSideProps와 같은 데이터 패칭 함수가 전혀 필요하지 않다. App Router 구조에서는 서버 컴포넌트 자체가 SSR의 진입점이 되며, 파일 상단에 use client 디렉티브가 없는 컴포넌트는 자동으로 Next.js가 서버 컴포넌트로 인식한다.
따라서 App Router에서 SSR을 구현하는 일은 생각보다 단순하다. 별도의 데이터 패칭 함수 없이, 서버 컴포넌트(예: page.tsx) 내에서 await를 활용해 직접 데이터를 불러오고, 이를 JSX에 렌더링하면 된다.
현재 디렉토리 구조는 다음과 같이 구성되어 있다( 참고로, 디렉토리 구조는 tree src로 조회 가능하다 ).
1➜ wetopia git:(main) ✗ tree src 2src 3├── app 4│ ├── layout.tsx 5│ └── page.tsx 6├── components 7│ ├── base 8│ ├── block 9│ └── domain 10│ │ └── stock 11│ │ ├── index.ts 12│ │ ├── StockChart.tsx 13│ │ └── StockChartContainer.tsx 14├── constants 15├── hooks 16│ ├── index.ts 17│ └── useStockDashboard.ts 18├── lib 19│ └── api 20│ ├── axios.ts 21│ └── stock.api.ts 22├── providers 23│ ├── index.ts 24│ ├── clientProvider.tsx # <-- ChakraProvider + RecoilRoot 25│ └── reactQueryHydrator.tsx # <-- React Query Client Provider 26... 27 2816 directories, 32 files
이 구조는 서버에서 데이터를 미리 패칭하고, 클라이언트에서 hydrate하는 구조에 최적화되도록 초점을 맞췄으며, /components/* 경로에 클라이언트 컴포넌트를 배치하고, 공용 훅 및 API 레이어는 각각 /hooks와 /lib/api에 분리시켰다. (혹여 서버 컴포넌트 또는 hydrate에 대해 궁금하다면 정리해둔 게시글을 참고하자)
API 관리 방식
/constants/endponts.ts는 앞으로 붙이게 될 엔드포인트들을 모아둔 파일이다. ${API_ENDPOINTS.STOCK.DASHBOARD} 방식으로 가져다쓰면 명시적이고, 앤드포인트가 많아질수록 유지보수하기에 좋다.
1// src/constants/endpoints.ts 2const API = "/api"; 3 4export const API_ENDPOINTS = { 5 STOCK: { 6 DASHBOARD: `${API}/stock/dashboard`, 7 // DETAIL: (symbol: string) => `${API}/stock/${symbol}`, 8 }, 9 // ... 10};
위 엔드포인트로 실제 API를 다음과 같이 구성한다.
1// src/lib/api/stock.api.ts 2 3import { API_ENDPOINTS } from "@/constants"; 4import { axiosInstance } from "./axios"; 5 6export const getStockDashboard = async () => { 7 const res = await axiosInstance.get(API_ENDPOINTS.STOCK.DASHBOARD); 8 return res.data; 9};
page.tsx
이제 실제 서버 컴포넌트에 주가 데이터를 SSR로 받아오는 코드를 작성한다. Next.js 서버 컴포넌트에서 await getStockDashboard()만으로도 SSR 방식으로 API 호출이 가능하다.
하지만 이 데이터를 React Query와 함께 사용할 것이기 때문에, 몇 가지 절차를 추가로 거쳐야 한다. 먼저, queryClient 인스턴스를 생성한 뒤, prefetchQuery()를 통해 서버에서 데이터를 미리 받아 React Query 캐시에 저장한다. 이후 dehydrate()를 통해 해당 캐시 상태를 클라이언트에 전달해줘야한다.
1import { ReactQueryHydrator } from "@/providers"; 2import { dehydrate, QueryClient } from "@tanstack/react-query"; 3 4export default async function Home() { 5 const queryClient = new QueryClient(); // 1. 인스턴스 생성 6 7 await queryClient.prefetchQuery({ 8 // 2. 데이터 패칭 + 캐싱 9 queryKey: STOCK_QUERY_KEYS.dashboard(), 10 queryFn: getStockDashboard, 11 }); 12 13 const dehydratedState = dehydrate(queryClient); // 3. dehydrate 14 15 return ( 16 // 4. dehydrate된 상태를 ReactQueryHydrator에 전달 17 <ReactQueryHydrator dehydratedState={dehydratedState}> 18 <Box px={6} py={2}> 19 <StockContainer /> 20 </Box> 21 </ReactQueryHydrator> 22 ); 23}
이처럼 1 -> 2 -> 3 -> 4 단계를 통해 React Query 기반의 SSR을 구현할 수 있다. 추가된 코드는 10줄이 채 되지 않지만, 처음 본다면 왜 저런게 필요한지, 감싸고 있는 <ReactQueryHydrator />는 또 뭔지 궁금할게 분명하다.
React Query
주가와 같은 외부 데이터는 캐시 전략이 더욱 중요한 데이터다. CSR 방식에서는 useEffect 안에서 데이터를 불러오기 때문에, 초기 화면은 비어 있는 상태로 노출이 된다. 사용자는 아무것도 없는 화면을 마주하게 되고, 그 데이터의 크기나 로딩 시간에 따라 LCP 등 성능 지표에도 부정적인 영향을 준다.
이러한 CSR의 한계는 SSR로도 어느정도 커버 가능하다. 그렇다면 React Query는 왜 사용하는가?
필요성
단순 SSR은 "초기 화면을 그려주는 것"에 초점을 맞춘다. 하지만 클라이언트 측에서의 인터랙션, 데이터 재요청, 캐시 전략 등 전체 사용자 흐름을 제어하기에는 한계가 있다. 이러한 "데이터 흐름 전반"을 관리하는 것이 React Query의 역할이다.
즉, 단순히 서버에서 데이터를 받아오는 것을 넘어서, 다음 기능을 제공한다.
-
클라이언트 전환 이후에도 데이터 재사용(
hydrate된 캐시 활용) -
중복 요처방지 및 불필요한 로딩 제거
-
자동 리패칭, 에러 재시도, 포커스시 갱신 등 풍부한 UX 제어
따라서, SSR + React Query의 조합은 선택의 문제 이상의 필수 전략에 가깝다..!
동작 방식
위 코드를 포함한 전체 동작 흐름을 알아보자. 서버 컴포넌트 동작을 알지 못하면 이해하기가 어려워 정리해준 게시글을 참고하면 좋겠다.
React Query 기반 SSR 동작은 크게 두 단계로 나뉜다.
-
서버 컴포넌트: 데이터를 미리 패칭하고 캐시에 저장된
-
클라이언트 컴포넌트: 미리 저장된 캐시를
hydrate하여 재사용
이 흐름에서 React Query의 HydrationBoundary가 서버와 클라이언트의 캐시 상태를 연결하는 핵심 역할을 한다.
서버 컴포넌트
1. 데이터 패칭
1const queryClient = new QueryClient(); 2await queryClient.prefetchQuery({ 3 queryKey: STOCK_QUERY_KEYS.dashboard(), 4 queryFn: getStockDashboard, 5});
QueryClient 인스턴스를 생성한 뒤, prefetchQuery()를 통해 데이터를 미리 패칭한다.
2. 캐시 직렬화(dehydrate)
React Query는 1번을 통해 받아온 데이터 상태를 클라이언트로 넘기기 위해 dehydrate()라는 메서드를 제공한다. 이렇게 미리 패칭해온 데이터를 React Query로 보관하고 있다가 클라이언트 측에서 useQuery로 사용할 때, 이미 캐시가 존재한다면 다시 받아오지 않고 재사용할 것이다.
hydrate vs dehydrate
dehydrate을 제공한다고 알고 넘어가기엔 우리에게 너무 익숙한 단어가 있다. 바로 hydrate다.
-
기존의 React
hydrate는, SSR로 생성된 HTML에 대해 클라이언트 JS가 이벤트 핸들러를 붙이고 인터랙션을 복원하는 과정이다. -
반면, React Query의
dehydrate는, 서버에서 생성한 캐시 상태를 JSON 형태로 직렬화하여 클라이언트로 전달하는 작업이다.
이 두 개념은 "단순히 반대 관계"라기보다는, 서로 연결된 "직렬화"와 "복원"의 개념으로 이해하는게 필자는 더 편했다.
따라서, dehydrate는 React Query가 클라이언트가 다시 hydrate할 수 있도록 서버의 상태를 전달 가능한 형태(JSON)로 바꾸는 과정을 말한다.
직렬화란?
솔직히 와닿지 않는다. 이건 이래요 라고 알고 넘어가기에 아직 모호한 느낌이다. 그렇다면 이렇게 설명하면 어떨까? 직렬화는 복잡한 데이터 구조(객체, Map, Set 등)을 네트워크나 파일로 전송할 수 있도록 문자열(JSON 등) 형태로 일렬로 나열해 변환하는 과정을 의미한다.
예를 들어, 서버에서 다음과 같은 상태를 React Query가 가지고 있다고 가정하자.
1// 직렬화 이전(복잡한 객체 상태) 2const state = { 3 status: "success", 4 data: { price: 123.45 }, 5 error: null, 6};
이 상태는 곧바로 클라이언트로 전송할 수 없다. dehydrate()를 통해 직렬화하면 아래와 같이 변환된다.
1{ 2 "queries": [ 3 { 4 "queryKey": ["stock"], 5 "state": { 6 "status": "success", 7 "data": { "price": 123.45 }, 8 "error": null, 9 "isFetching": false 10 } 11 } 12 ] 13}
이렇게 변환된 JSON은 HTML의 <script> 태그나 네트워크 응답 본문에 담아 브라우저로 안전하게 전달된다(번외로, JSON.stringify() 역시 직렬화 방식이다).
추가로 기억하자: 클라이언트에 값을 전달하려면 반드시 "순수 JSON"이어야 한다. React 자체도 (props도 그렇지만) 직렬화 가능한 값만 허용하며, 브라우저와 서버 간 통신 역시 문자열 기반이다. 이 때문에 React Query의 내부 캐시 구조도 반드시 직렬화 과정을 거쳐야만 한다.
클라이언트 컴포넌트
클라이언트 측에서는 서버에서 직렬화된 상태(dehydratedState)를 React Query의 HydrationBoundary를 통해 복원(hydrate)한다. 이렇게 복원된 상태는 useQuery()에서 별도의 네트워크 요청 없이 즉시 사용 가능하다.
1<QueryClientProvider client={queryClient}> 2 <HydrationBoundary state={dehydratedState}>{children}</HydrationBoundary> 3</QueryClientProvider>
HydrationBoundary의 역할
좀 더 자세히 살펴보자. HydrationBoundary는 내부적으로 hydrate()를 실행하여, 이 JSON을 QueryClient의 캐시로 되살린다.
우선, dehydratedState는 서버로부터 전달 받아온 단순 JSON이다. 하지만 이 JSON은 여전히 React Query 입장에서는 "캐시"가 아닌 단순 데이터로 취급된다.
단순 데이터로 취급되지 않기 위해서 어떻게 해야할까? 클라이언트에서 이를 실제 캐시로 사용하려면, hydrate() 과정을 거쳐 React Query의 QueryClient 내부에 주입해줘야 한다. HydrationBoundary는 이 hydrate() 과정을 자동으로 수행해주며, 클라이언트에 도착한 JSON 데이터를 다시 React Query가 사용할 수 있는 정식 캐시로 복원해준다.
이 덕분에 위에서 언급했던 useQuery() 동작이 가능하다. useQuery()는 해당 쿼리 키에 대한 캐시가 이미 존재한다는 사실을 인식하고, 불필요한 네트워크 요청 없이 즉시 캐시된 데이터를 반환할 수 있게 된다. 이로써 사용자 입장에서는 빠른 렌더링, 즉각적인 데이터 표시라는 경험을 누릴 수 있다.
코드 적용 및 정리
설명이 너무 주절 주절 많았다. 그치만 이해하기 위해서 최대한 필요한 설명과 예시를 들어야헀다(타자료 없이 이 글만 보면 전부 이해되기 위함이다).
자, 이제 동작 흐름도 알았겠다 최종 정리해보고 얼른 테스트 결과를 살펴보자!
page.tsx
서버 컴포넌트 진입점인 page.tsx 코드부터 살펴보면,
1export default async function Home() { 2 // 1. QueryClient 인스턴스를 생성하고 3 const queryClient = new QueryClient(); 4 5 // 2. prefetchQuery() 로 서버에서 미리 데이터를 불러온다. 6 await queryClient.prefetchQuery({ 7 // 2-1. 해당 키로 quertClient 내부에 캐시를 저장한다 8 queryKey: STOCK_QUERY_KEYS.dashboard(), 9 queryFn: getStockDashboard, 10 }); 11 12 // 3. dehydrate 호출로 JSON 직렬화 진행한다. 13 const dehydratedState = dehydrate(queryClient); 14 15 return ( 16 <ReactQueryHydrator dehydratedState={dehydratedState}> 17 <Box px={6} py={2}> 18 <StockContainer /> 19 </Box> 20 </ReactQueryHydrator> 21 ); 22}
StockContainer.tsx / useStockDashboard.tsx
StockContainer는 클라이언트 컴포넌트이며, 내부에서 useStockDashboard 훅을 통해 데이터를 가져온다. 이 훅 내부에서 useQuery가 사용되는데, SSR 단계에서 미리 캐시된 쿼리 키가 존재하기 때문에 클라이언트에서는 별도의 fetch 없이 이미 존재하는 캐시를 즉시 사용하게 된다.
이 구조 덕분에 사용자는 Spinner나 깜빡임 없이, 마치 정적 콘텐츠처럼 즉시 데이터를 확인할 수 있는 UX를 경험하게 된다.
1// src/components/domain/stock/StockContainer.tsx 2"use client"; 3 4export default function StockContainer() { 5 const { data, isLoading, isError } = useStockDashboard(); 6 7 // ... 생략 8 9 return ( 10 <Box py={4}> 11 <Heading size="md" mb={4}> 12 {STOCK_CONTAINER_TITLE} 13 </Heading> 14 {data.map((stock) => ( 15 <Box key={stock.symbol} mb={6}> 16 <Text>{stock.symbol}</Text> 17 {/* 차트 등 시각화 구성 */} 18 </Box> 19 ))} 20 </Box> 21 ); 22} 23 24// src/hooks/useStockDashboard.tsx 25export const useStockDashboard = () => 26 useQuery({ 27 queryKey: STOCK_QUERY_KEYS.dashboard(), 28 queryFn: getStockDashboard, 29 staleTime: 1000 * 60 * 5, // 5분 동안 fresh 30 retry: 2, 31 refetchOnWindowFocus: false, 32 });
ReactQueryHydrator.tsx
이 컴포넌트 역시 클라이언트 컴포넌트로, SSR 과정에서 직렬화된 상태(dehydratedState)를 전달받아 React Query 클라이언트의 초기화 및 캐시 복원(hydration) 역할을 수행한다.
다음과 같은 역할을 한다.
-
클라이언트에서
QueryClient인스턴스를 생성한다. -
QueryClientProvider로 전역 쿼리 클라이언트를 감싼다. -
HydrationBoundary를 통해 전달받은JSON(dehydratedState)을 React Query 내부 캐시로 복원한다. -
Devtools를 붙여서 쿼리 상태를 시각적으로 확인할 수 있도록 한다.
1// src/providers/ReactQueryHydrator.tsx 2"use client"; 3 4export default function ReactQueryHydrator({ 5 children, 6 dehydratedState, 7}: { 8 children: ReactNode, 9 dehydratedState: unknown, 10}) { 11 const [queryClient] = useState(() => new QueryClient()); // 클라이언트용 초기화 12 13 return ( 14 <QueryClientProvider client={queryClient}> 15 <HydrationBoundary state={dehydratedState}> 16 <> 17 {children} 18 {process.env.NODE_ENV === "development" && ( 19 <ReactQueryDevtools initialIsOpen={false} /> 20 )} 21 </> 22 </HydrationBoundary> 23 </QueryClientProvider> 24 ); 25}
Provider로 취급하여 분리한 이유
ReactQueryHydrator는 SSR을 통해 전달받은 dehydratedState를 클라이언트에서만 복원할 필요가 있기 때문에, 별도의 컴포넌트로 분리하였다.
분리한 덕분에,
-
SSR이 적용된 페이지에서는
ReactQueryHydrator만으로 SSR + Hydration 처리가 가능하고, -
일반적인 페이지나
layout.tsx에서는 기존ClientProvider를 유지할 수 있다.
코드 실행
여태까지의 코드를 yarn dev로 실행하면 성공적으로 렌더링되는 것을 확인할 수 있다. SSR이 성공적이라는 것을 알기 위해, 개발자 도구에서 네트워크탭을 통해 온 데이터를 살펴보자. CSR 방식에서 API 호출로 받아올 데이터가 이미 입혀진 채로 HTML을 받아온 것이 확인 가능하다.
 localhost:3000
localhost:3000
Devtools
위 스크린샷을 보면 렌더링 화면의 우측 하단에 "섬 아이콘"을 볼 수 있다. ReactQueryHydrator.tsx 코드를 보면 <ReactQueryDevtools initialIsOpen={false} /> 를 볼 수 있다.
1{ 2 process.env.NODE_ENV === "development" && ( 3 <ReactQueryDevtools initialIsOpen={false} /> 4 ); 5}
ReactQueryDevtools는 React Query에서 제공하는 개발자 도구로, 현재 캐시된 쿼리 상태, 쿼리 키, 상태 변화(Fetching, Stale, Success 등), 네트워크 요청 발생 여부 등을 시각적으로 확인할 수 있게 해주는 도구이다.
이를 통해 useQuery()가 실제 네트워크 요청을 보내는지, 각 쿼리의 staleTime, isFetching 등 여부로 실시간으로 확인 가능해서 편리하다.
 react query devtools
react query devtools
위 캡쳐된 사진을 보면,
-
status: "success",fetchStatus: "idle"로 표시되는 것을 볼 수 있다. 이는 클라이언트 측에서 별도의 네트워크 요청 없이, 서버에서 전달된 캐시된 데이터를 즉시 활용하고 있다는 것을 의미한다. -
error: null,isInvalidated: false로 나타나는 것을 보면, 쿼리는 정상적으로 처리되어 유효한 상태인 것이 확인 가능하다.
이처럼 Devtools를 활용하면 SSR이 제대로 적용되었는지 직관적으로 검증할 수 있다.
성능 테스트
React Query 기반 SSR 적용을 마쳤고, 렌더링 성능은 이미 유의미한 차이를 보인다.
두 렌더링 방식(CSR vs SSR)의 성능 분석을 수치화하기 위해 Lighthouse로 각각 분석해본 결과 다음과 같이 나온다.
 CSR/SSR Lighthouse 분석 결과
CSR/SSR Lighthouse 분석 결과
LCP
- CSR: 8.2s
- SSR: 0.6s
사용자가 페이지가 떴다고 인식하는 핵심 지표이자 가장 큰 컨텐츠 요소가 렌더링되기까지 걸리는 시간으로, CSR 방식에서의 LCP는 8200ms로 구글 권장 기준으로는 Poor 상태인 4000ms초보다 2배나 느리다. SSR을 통해 약 92% 개선되었다.
LCP 지연의 핵심 원인: JS 실행 지연 및 렌더링 딜레이
 Lighthouse/Performance 상세
Lighthouse/Performance 상세
Lighthouse가 제공해주는 세부 원인(위 사진 참고)을 살펴보면, 무려 8,200ms가 측정된 LCP 요소는 <h2 class="chakra-heading">AMD · Advanced Micro Devices</h2>이다. 이 텍스트가 렌더링되기까지 걸린 시간의 98%가 Render Delay였다. 즉, DOM이 이미 로드되고도 실제 컨텐츠가 사용자에게 보이기까지 렌더링 자체가 늦게 발생한 것이다. 게다가, 이는 곧 JS가 너무 늦게 실행되고 있다는 문제와 연계된다.
JS 실행 딜레이
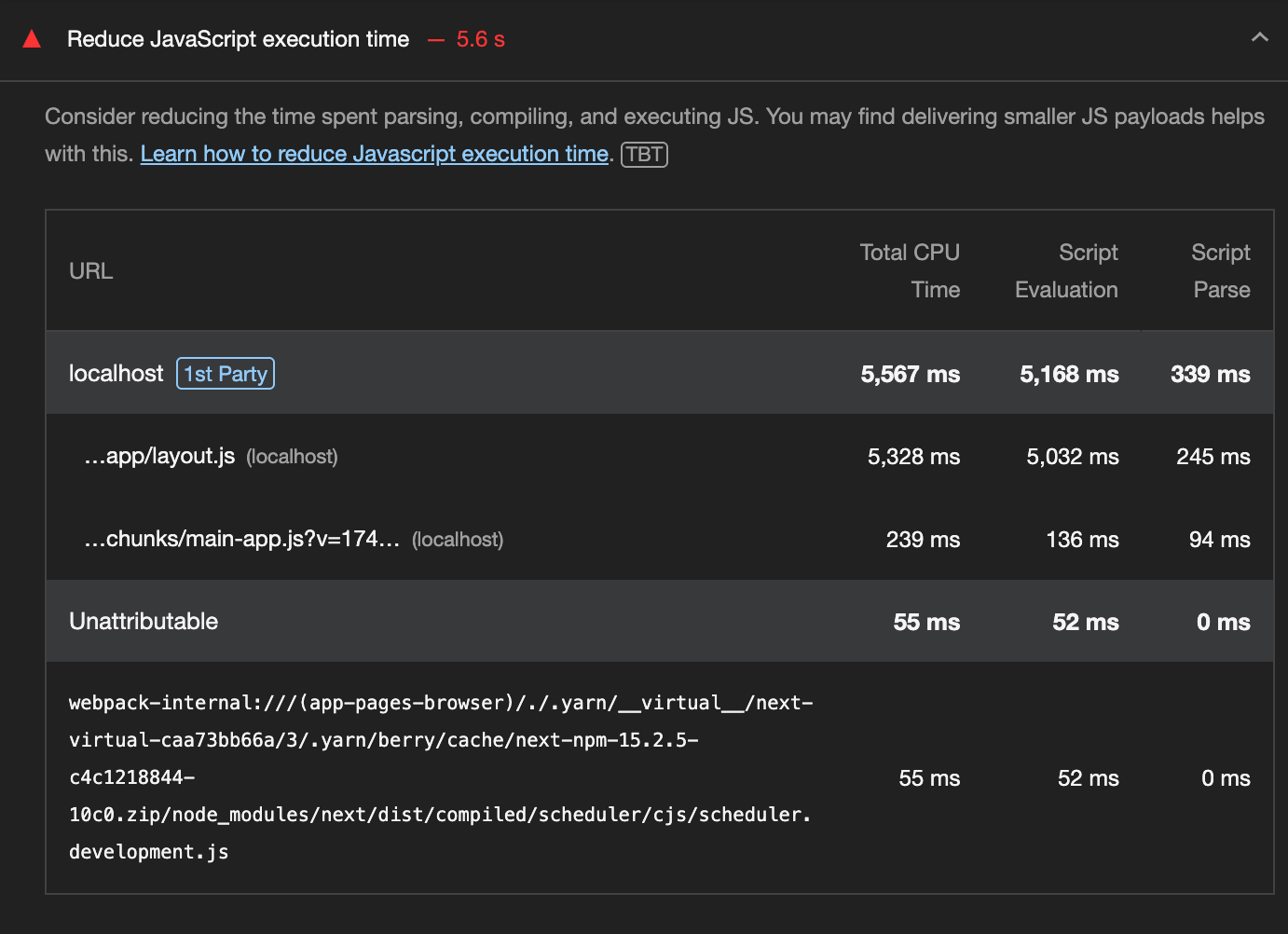
CSR 방식에서 총 JS 실행 시간이 5,567ms에 달한다. 특히, app/layout.js 하나에서만 5.3초가 소모되었고, 이로 인해 메인 스레드가 장시간 점유되었다. 이는 CSR 구조에서 전체 초기 화면은 JS로 구성해야하기 때문에 불가피한 문제다.
혹여 layout.js에서 왜? 라는 의문이 가진다면, app/layout.js는 App Router에서 모든 페이지 렌더링의 루트 컴포넌트이기 때문에, 페이지 진입 시 가장 먼저 로드되고, 공통 레이아웃, 글꼴, 테마, 상태관리, 글로벌 스타일, 외부 라이브러리 초기화 등 모두 여기에 집중되어있다.
현재 프로젝트 기준, Chakra UI, Recoil, React Query, emotion 등 여러 컨텍스트 프로바이더들이 래핑되어있어 초기 JS 실행 시간이 증가하였다.
메인 스레드 점유현황
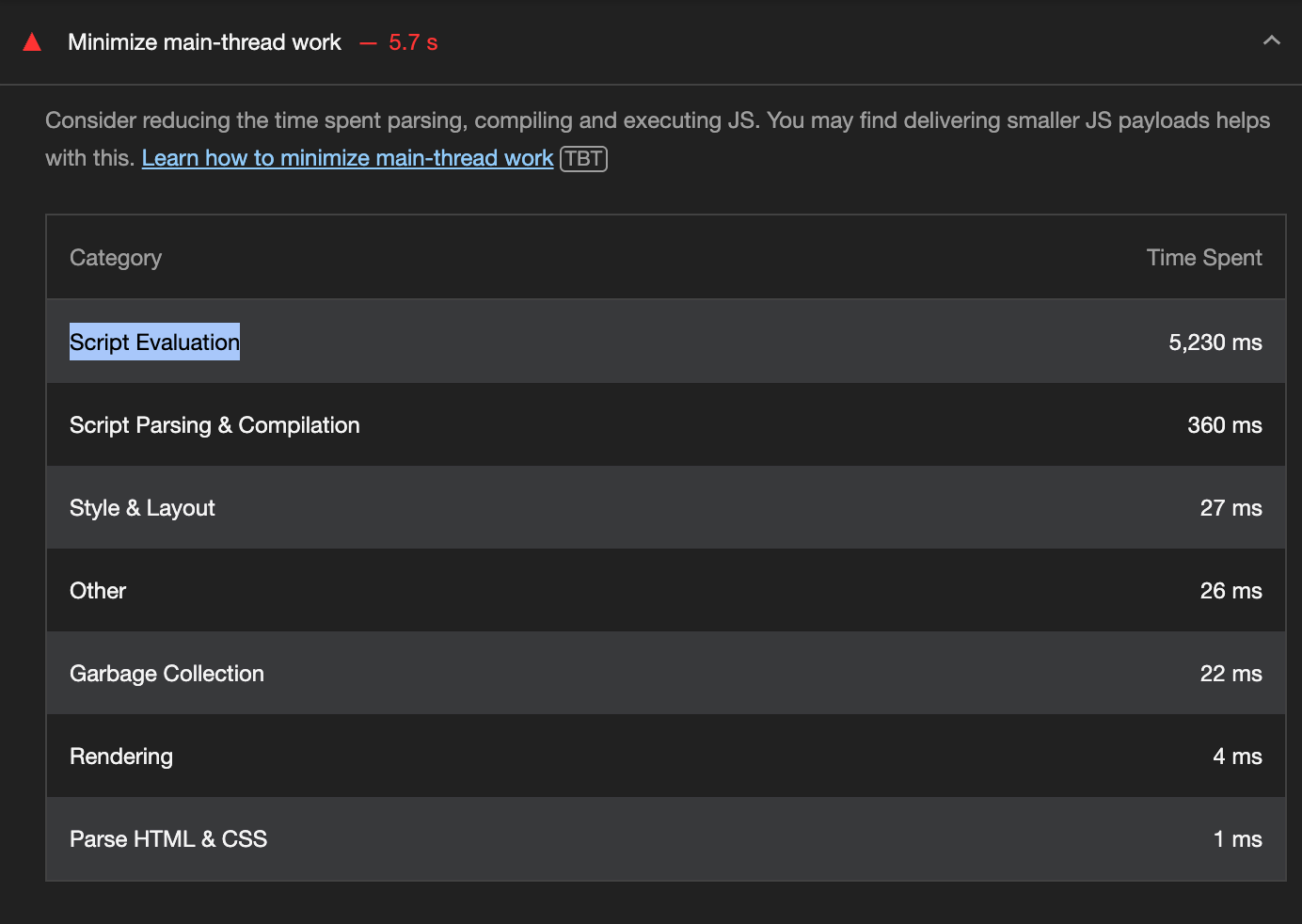
상세 내용을 보면, Script Evaluation, Parsing, Compliation 등 JS 관련 처리로만 90% 이상의 메인 스레드 작업이 발생했다. 이 역시 위에서 말한 초기 페이지가 로드되더라도 사용자가 육안이 확인하기 위한 화면은 JS 처리가 끝난 뒤에야 가능하기 때문에 문제인 것이다.
이 밖에도 사용되지 않는 JS 문제 및 번들 과다 현상 등 세부적인 내용을 관측 가능하지만, LCP을 가장 크게 다루기 때문에 이하 내용은 생략한다.
이제 LCP 외 지표를 살펴보자.
TBT
- CSR: 250ms
- SSR: 180ms
TBT(Total Blocking Time)은 JS 실행 등으로 인해 메인 스레드가 막혀 사용자 입력 응답이 지연된 총 시간에 대한 지표다. CSR에서는 JS 실행량이 많아 증가하는 반면, SSR은 HTML을 먼저 제공하기에 초기 JS 실행 부담이 줄어들었다. 약 28% 개선되었다.
SI
- CSR: 3.2s
- SSR: 1.9s
SI(Speed Index)는 시각적으로 컨텐츠가 화면에 표시되는 속도의 평균값으로, SSR이 렌더링된 HTML을 즉시 제공하여 사용자는 컨텐츠를 더욱 빠르게 인식한다. SI는 약 40% 개선되었다.
분석 정리
CSR은 모든 렌더링을 브라우저가 맡게 되어 초기 로딩 시점에 JS 처리량이 많고, 이는 메인 스레드의 병목으로 이어진다. 실제 분석 결과를 바탕으로,
-
LCP 지연의 98%가 JS 실행 이후의 렌더링 지연에서 발생
-
layout.js파일 하나만으로도 5.3초 이상의 JS 실행 시간 -
전체 메인 스레드 작업 시간이 5.7초 도달
반면, SSR은 서버에서 HTML을 사전 렌더링하여 클라이언트에서는 즉시 컨텐츠를 볼 수 있다. React Query를 활용하여 데이터 prefetch 및 hydration 구조는 초기 HTML에 데이터를 주입하여 최초 요청은 빠르되, 이후 상태 관리도 클라이언트에서 자연스레 유지된다.
따라서, SSR + React Query 조합은 다음 항목을 통해 CSR 방식의 단점을 해소한다.!
-
서버에서 렌더링된 HTML을 통해 즉시 컨텐츠 노출
-
JS 실행 부담 감소로 메인 스레드 병목 해소
-
React Query의 hydration으로 동적 상태 유지
이러한 성능 개선은 단순 수치 향상을 넘어 실제 사용자의 이탈률 감소와 전반적인 서비스 만족도까지 이어질 수 있다. 게다가 서버에서 처리하는 과정으로 인해 SEO 최적화까지 이점을 취할 수 있다. 종합적으로 볼 때, Lighthouse 기준 성능 점수는 58점 → 91점으로 약 57% 향상되었고, 특히 사용자 체감 성능에 직결되는 LCP는 약 92% 개선되었다.
개선 사항
SSR을 적용하고자하는 서버 컴포넌트는 무조건 <ReactQueryHydrator />로 감싸주어야한다. 만약 프로젝트 규모가 커짐에 따라 여러 라우터에서 매번 <ReactQueryHydrator />로 감싸줘야한다면 코드 작성에 대한 비용과 추후 수정 여부에 따라 발생할 사이드 이팩트가 커지지 않을까?
헬퍼 함수 추상화
SSR 대상 서버 컴포넌트에 반복되는 QueryClient, prefetchQuery, dehydrate, <ReactQueryHydrator /> 구조를 재사용 가능하게 추상화시킨다.
1export async function withSSRHydration( 2 fn: (queryClient: QueryClient) => Promise<React.ReactNode> 3) { 4 const queryClient = new QueryClient(); 5 6 const content = await fn(queryClient); 7 const dehydratedState = dehydrate(queryClient); 8 9 return ( 10 <ReactQueryHydrator dehydratedState={dehydratedState}> 11 {content} 12 </ReactQueryHydrator> 13 ); 14}
withSSRHydration 함수로 기존 서버 컴포넌트 진입점인 page.tsx를 아래와 같이 감싸준다. 테스트 결과 기존과 동일하게 정상 동작한다.
1export default async function Home() { 2 return withSSRHydration(async (queryClient) => { 3 await queryClient.prefetchQuery({ 4 queryKey: STOCK_QUERY_KEYS.dashboard(), 5 queryFn: getStockDashboard, 6 }); 7 8 return ( 9 <Box px={6} py={2}> 10 <StockContainer /> 11 </Box> 12 ); 13 }); 14}
이로써, 라우터별 반복되는 불필요 코드가 제거되었고, 추후 ReactQueryHydrator의 내부 로직이 변경될 시 전역 반영이 가능해져서 구고적인 일관성을 가질 수 있게 되었다. 앞으로 새로운 페이지마다 이 함수만 붙이면 문제없이 동작할 것이다.
마치며
여태까지 SSR과 React Query를 어떻게 병행해서 사용하는지 살펴보았다. 얼마 전에 그런 글을 읽었다. 좋은 기술 블로깅이란, "단순히 지식을 나열하는 글"이 아닌 "실무자가 끝까지 읽어낼 수 있는 임팩트가 있는 글"이라는 내용이었다. 따라서, 이번 게시글은 그런 생각을 바탕으로 작성되었으며, 앞으로도 그런 고민을 하면서 포스팅해볼 생각이다.